

Since ChatGPT was announced, there’s been a ton of discussion around the impact of AI generated content - especially when it comes to content creation by writers. While we generally believe that AI assisted writing can help writers tremendously with their job, generative models like ChatGPT potentially open up a Pandora's box of low-quality content.
Shortly after ChatGPT 3 was released to the public, our team came together for a brainstorming session about how this will influence the writer’s ecosystem. Over the following weeks, it became apparent that authenticity in the form of human written content is a topic content creators and readers deeply care about.
That’s why we started to work on a solution which would attest writers that their texts are in fact human written. There are already some human writer badges that people can download and just put on their website or blog, but we wanted to give a solid evidence to writers using Authory.
This turned out to be a hard problem. Generative AI is already quite powerful. It’s possible to generate good text, especially given the right input. There are tools which claim to be able to detect AI-generated texts, but those tools are quickly thrown off even by minor edits. OpenAI, the company behind ChatGPT, released a detector for AI written text, but they themselves stated that the tool is not reliable. Other commercial tools we looked into also did not convince us in terms of accuracy.
However, Authory has one big advantage: Since we maintain an archive of all our customer’s content, we know their style of writing incredibly well.
Content Fingerprinting
The central idea behind Authory’s Human Writer certificate is to create a fingerprint for each author which represents the author’s writing style. In fact, we compute many fingerprints per person and pick the most relevant ones. The reason is that the writing style can differ a lot for the same writer, based on the target audience or the exact format of an article. An interview naturally has a very different flow compared to an opinion piece.
To reliably isolate the writing style without potentially capturing AI generated input, we only use content from before December 2022 for computing the fingerprints.
For each of these content pieces, we generate an embedding using a large-language model that we trained specifically on generating embeddings based on style on about a million articles. An embedding is essentially a mapping of some input (in our case text) to a vector, where semantically similar vectors (in our case similar writing style) are placed closer together. The model ignores the actual content of the text and only focuses on style.
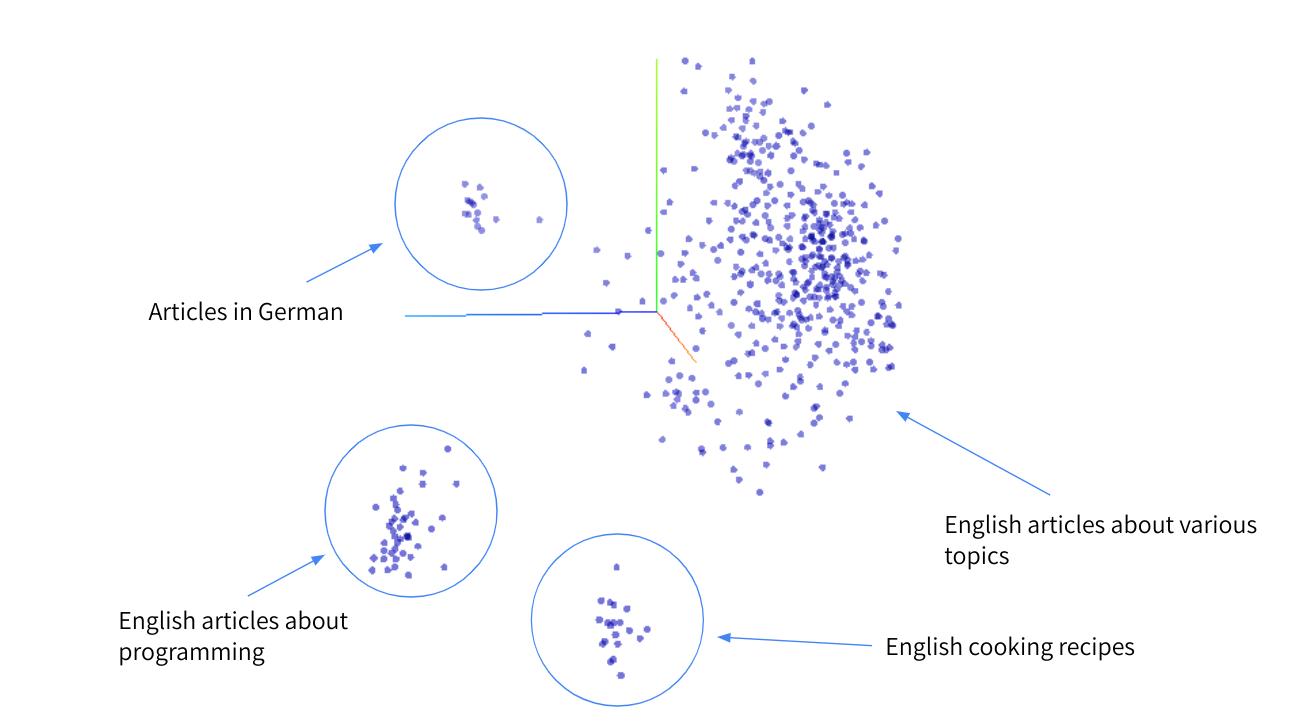
The above chart is a visualization of a clustering for a user writing on different platforms, about different topics, in different languages. We can observe different clusters of content. Intuitively speaking, similar formats are placed close together. The large cluster contains many long-form pieces about different topics. Articles about programming and cooking recipes are clustered separately, because they have a very distinct flow - articles about programming contain a lot of code, cooking recipes contain lists of ingredients and instructions.
The visualization was generated using t-SNE, an algorithm that can embed high-dimensional information into a more convenient space. While the above is a 3D visualization, the actual embeddings are 32-dimensional and capture way more details than can be represented in the chart above.
Awarding the Certificate
Given an embedding for each content item, we use a hierarchical clustering algorithm to identify clusters. Simply put, content items with similar embeddings are merged recursively, until we end up with larger clusters that contain all similar embeddings. The averaged embeddings of each cluster are then saved as the author’s fingerprint.
This fingerprint represents all the writing styles the author has had during their career.
Now, we attempt to detect outliers for newer articles. We compute embedding for all articles written after December 2022, when ChatGPT became broadly available. Then, we match these embeddings with the list of embeddings in the fingerprint.
Only if the clear majority of new articles matches the author’s known writing style, the Human Writer certificate is awarded.
We do not strictly require all articles to match clusters, since our experiments showed that there is almost always a number of outliers in the dataset. In fact, it is usually not even possible to assign all articles of an author into clusters.
Test Results
We verified this approach with a group of writers of whom we know they used ChatGPT to write articles, as well as a control group of writers of whom we know they did not use ChatGPT.
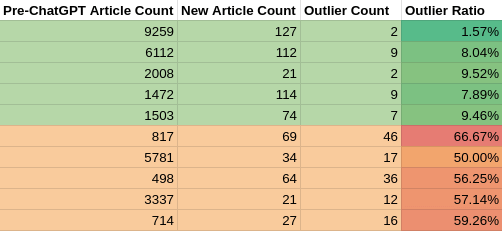
The control group not using any AI tools to write texts had about 20,000 articles written before December 2022 in total. They wrote roughly 500 articles since December 2022, which were checked for outliers. The ratio of outliers was consistently below 10%.
The group which used ChatGPT had roughly 11,000 articles written before December 2022. They wrote 220 articles since December 2022, which we checked for outliers. The ratio of outliers was consistently at or above 50%.
We want to emphasis that the LLM used for generating embeddings was trained unsupervised. The goal was to minimize the L2 distance between embedding vectors for the same author, while maximizing the distance to embeddings for other authors. We verified the quality of embeddings with a distinct test dataset.
Acknowledgements
Big shout out to Kathrin from RYVER.AI, Camiel from birds.ai and Martin for all their input and sparring regarding the fingerprinting approach & implementation.
